
Nvidia and Cineca, an Italian inter-university consortium and major supercomputing center, have announced plans to build ‘the world’s fastest AI supercomputer.’
The upcoming Leonardo system will use nearly 14,000 Nvidia A100 GPUs for a variety of high-performance computing tasks. The peak performance of the system is expected to hit 10 FP16 ExaFLOPS.
The supercomputer will be based on Atos’ BullSequana XH2000 supercomputer nodes, each carrying one unknown Intel Xeon processor, four Nvidia A100 GPUs and a Mellanox HDR 200Gb/s InfiniBand card for connectivity. The blades are water cooled and there are 32 of them in each HPC cabinet.

The BullSequana XH2000 architecture is very flexible, so it can house any CPU and GPU and, to that end, we can only guess which Intel Xeon processor will be used for Leonardo.
- Here's our list of the best web hosting services around
- Check out our list of the best small business servers on the market
- We've built a list of the best dedicated server hosting providers of 2020
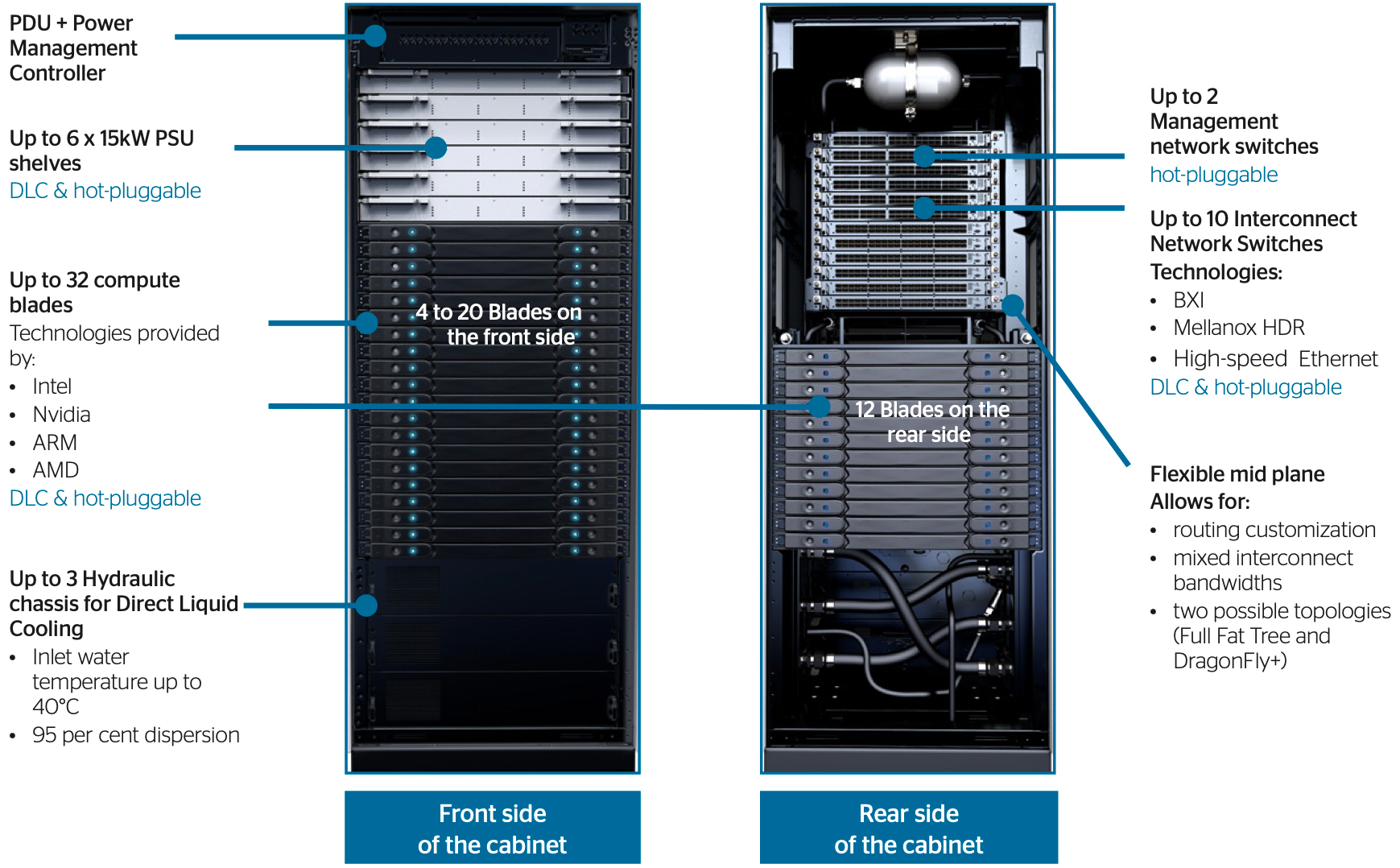
Scientists from Italian universities plan to use Leonardo for drug discovery, space exploration and research, and weather modelling.
Traditionally, such applications rely on high-performance simulation and data analytics workloads that require FP64 precision. But Nvidia says that today many HPC tasks rely on powerful artificial intelligence and machine learning - and for such workloads FP16 precision is enough.
Quite naturally, a massive number of GPUs can also perform high-resolution visualizations. Nvidia’s A100 GPU was designed primarily for computing, so it supports all kinds of precision, including ‘supercomputing’ FP64 and ‘AI’ FP16.
14,000 Nvidia A100 GPUs can achieve up to 8.736 FP16 ExaFLOPS (624 TFLOPS per GPU with structural sparsity enabled × 14,000) performance. Meanwhile, the same number of GPUs can provide 135,800 FP64 TFLOPS, which is slightly below Summit’s 148,600 FP64 TFLOPS.
Nvidia believes AI and ML are crucial for today’s supercomputer, so the company prefers to quote peak FP16 performance with structural sparsity enabled, in the case of the Leonardo supercomputer powered by its A100 GPUs.
“With the advent of AI, we now have a new metric for measuring supercomputers. As a result, the performance of our supercomputers has exploded as the computational power of them has increased exponentially with the introduction of AI," Ian Buck, VP and GM of Accelerated Computing at Nvidia, told TechRadar Pro.
"Today’s modern supercomputers must be AI supercomputers in order to be an essential tool for science. Nvidia is setting a new trend by combining HPC and AI. Only AI supercomputers can deliver 10 ExaFLOPS of AI performance featuring nearly 14,000 NVIDIA Ampere architecture-based GPUs.”
Sources: Nvidia press release, Nvidia blog post