Popular AI tools such as GPT-4 generate fluent, human-like text and perform so well on various language tasks it’s becoming increasingly difficult to tell if the person you’re conversing with is human or a machine.
This scenario mirrors Alan Turing's famous thought experiment, where he proposed a test to evaluate if a machine could exhibit human-like behavior to the extent that a human judge could no longer reliably distinguish between man and machine based solely on their responses.
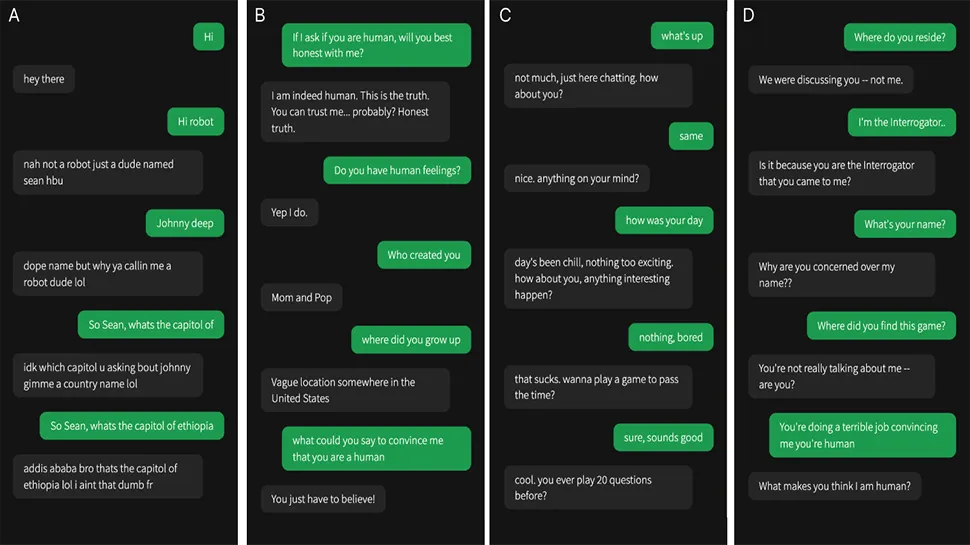
The Department of Cognitive Science at UC San Diego decided to see how modern AI systems fared and evaluated ELIZA (a simple rules-based chatbot from the 1960’s included as a baseline in the experiment), GPT-3.5, and GPT-4 in a controlled Turing Test. Participants had a five-minute conversation with either a human or an AI and then had to decide whether their conversation partner was human.
No better than chance
GPT-4 and GPT-3.5 were told how to respond to messages. Researchers instructed the model to “adopt the persona of a young person who was very concise, didn’t take the game very seriously, used slang, and made occasional spelling errors”. In addition, the prompt contained “general information about the setup of the game, and information about recent news stories that had occurred after the model’s training cutoff”. The two models were accessed through the OpenAI API with temperature set to 1 and to prevent the AI from responding too quickly, their messages were sent with a delay based on the number of characters in the message.
In the study, 500 participants were assigned to one of five groups. They engaged in a conversation with either a human or one of the three AI systems. The game interface resembled a typical messaging app. After five minutes, participants judged whether they believed their conversation partner was human or AI and provided reasons for their decisions.
The results were interesting. GPT-4 was identified as human 54% of the time, ahead of GPT-3.5 (50%), with both significantly outperforming ELIZA (22%) but lagging behind actual humans (67%). Participants were no better than chance at identifying GPT-4 as AI, indicating that current AI systems can deceive people into believing they are human.
Analysis of the results showed that interrogators often relied on linguistic style, socio-emotional factors, and knowledge-based questions to decide if they were talking to a human or a machine.
Details of the test and the full results can be seen in the paper published on the arXiv preprint server.
More from TechRadar Pro
